 Easi3R: Estimating Disentangled Motion from DUSt3R Without Training
Easi3R: Estimating Disentangled Motion from DUSt3R Without Training
Recent advances in DUSt3R have enabled robust estimation of dense point clouds and camera parameters of staticscenes, leveraging Transformer network architectures and direct supervision on large-scale 3D datasets. In contrast, the limited scale and diversity of available 4D datasets present a major bottleneck for training a highly generalizable 4D model. This constraint has driven conventional 4D methods to fine-tune 3D models on scalable dynamic video data with additional geometric priors such as optical flow and depths. In this work, we take an opposite path and introduce Easi3R, a simple yet efficient training-free method for 4D reconstruction. Our approach applies attention adaptation during inference, eliminating the need for from-scratch pre-training or network fine-tuning. We find that the attention layers in DUSt3R inherently encode rich information about camera and object motion. By carefully disentangling these attention maps, we achieve accurate dynamic region segmentation, camera pose estimation, and 4D dense point map reconstruction. Extensive experiments on real-world dynamic videos demonstrate that our lightweight attention adaptation significantly outperforms previous state-of-the-art methods that are trained or finetuned on extensive dynamic datasets.
We introduce the spatial and temporal attention mechanism behind DUSt3R, enabling robust dynamic object segmentation.
This segmentation efficiently disentangles object and camera motion, enabling DUSt3R to robustly reconstruct 4D.
4D Reconstruction
Static Scene
Dynamic Object




Here, we visualize cross-frame aligned static scenes with dynamic point clouds at a selected timestamp.
Instead of using GT dynamic masks, we use the estimated dynamic masks to filter out points at other timestamps.
Click tabs below to explore the results for each baseline.
Our method achieves superior structure alignment and fewer artifacts, owing to the robust dynamic segmentation estimation.




Our method provides clean reconstructions, while DAS3R suffers from structure misalignment and ghosting artifacts due to inaccuracies in dynamic segmentation estimation. For example, it under-segments the dog and goose.
CUT3R lacks support for dynamic mask estimation, leading to the blending of points from different frames when ground truth masks are not used. Additionally, our approach demonstrates greater reliability in achieving accurate camera poses.
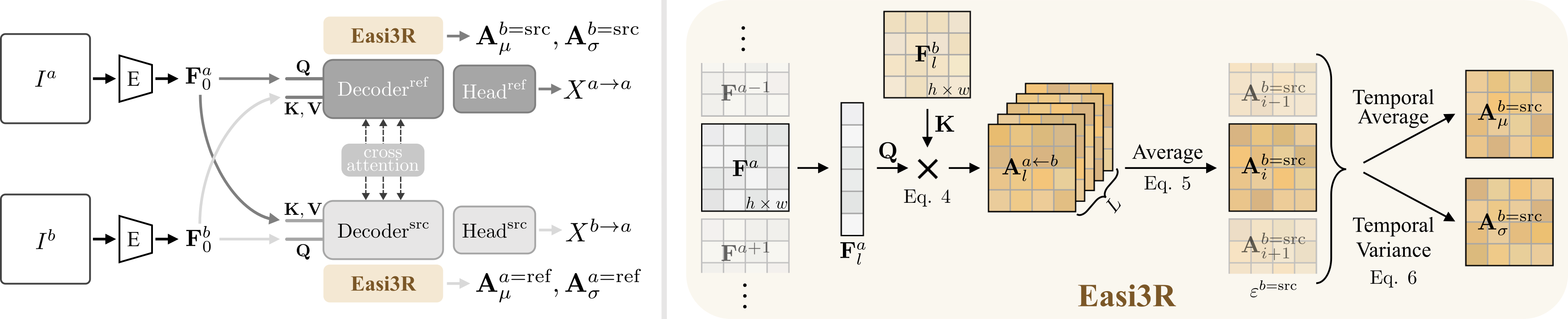
DUSt3R and our Easi3R adaptation. DUSt3R encodes two images \( I^a, I^b \) into feature tokens \( \mathbf{F}_0^a, \mathbf{F}_0^b \), which are then decoded into point maps in the reference view coordinate space using two decoders. Our Easi3R aggregates the cross-attention maps from the decoders, producing four semantically meaningful maps: \( \mathbf{A}^{b=\text{src}}_\mu, \mathbf{A}^{b=\text{src}}_\sigma, \mathbf{A}^{a=\text{ref}}_\mu, \mathbf{A}^{a=\text{ref}}_\sigma \). These maps are then used for a second inference pass to enhance reconstruction quality.
Our key insight is that DUSt3R implicitly learns rigid view transformations through its cross-attention layers. It assigns low attention values to tokens that violate epipolar geometry constraints. We propose to disentangle motions from the attention layers by aggregating cross-attention outputs across spatial and temporal dimensions.
Classic films in 4D, powered by Easi3R — unmute to enjoy the original audio🔊
@article{chen2025easi3r,
title={Easi3R: Estimating Disentangled Motion from DUSt3R Without Training},
author={Chen, Xingyu and Chen, Yue and Xiu, Yuliang and Geiger, Andreas and Chen, Anpei},
journal={arXiv preprint arXiv:2503.24391},
year={2025}
}
 ICCV 2025
ICCV 2025